ONNX Converter (Deprecated)
This document is for toolchain before v0.25.0. For users using later toolchain dockers, you can also manually switch to the
baseenvironment by runningconda activate base. However, this is not recommended as this tool is deprecated and will not be maintained in the future. Please use theonnx1.13environment instead.
ONNX_Convertor is an open-source project on Github.
The general process for model conversion is as following:
- Convert the model from other platforms to onnx using the specific converters. See section 1 - 5.
- Optimize the onnx for Kneron toolchain using
onnx2onnx.py. See section 6. - Check the model and do further customization using
editor.py(optional). See section 7
TIPS:
ONNX exported by Pytorch cannot skip step 1 and directly go into step 2. Please check section 2 for details.
If you're still confused reading the manual, please try our examples from https://github.com/kneron/ConvertorExamples. You can download the examples through these terminal commands:
git clone https://github.com/kneron/ConvertorExamples.git
cd ConvertorExamples && git lfs pullTable 1.2 shows supported operators conversion mapping table for every platform.
Table 1.2 Operators conversion table for every platform
| type | keras | caffe | tflite | onnx(Opset 11) |
|---|---|---|---|---|
| add | Add | Eltwise | ADD | Add |
| average pooling | AveragePooling2D | Pooling | AVERAGE_POOL_2D | AveragePool |
| batchnormalization | BatchNormalization | BatchNorm | BatchNormalization | |
| concatenate | Concatenate | Concat | CONCATENATION | Concat |
| convolution | Conv2D | Convolution | CONV_2D | Conv |
| crop | Cropping2D / Cropping1D | Slice | ||
| deconvolution | Conv2DTranspose | Deconvolution | TRANSPOSE_CONV | ConvTranspose |
| dense | Dense | InnerProduct | FULLY_CONNECTED | Gemm |
| depthwise convolution | DepthwiseConv2D | DepthwiseConvolution | DEPTHWISE_CONV_2D | Conv (with group attribute) |
| flatten | Flatten | Flatten | Flatten | |
| global average pooling | GlobalAveragePooling2D | Pooling | MEAN | GlobalAveragePool |
| global max pooling | GlobalMaxPooling2D | Pooling | GlobalMaxPool | |
| leaky relu | LeakyReLU | LEAKY_RELU | LeakyRelu | |
| max pooling | MaxPooling2D | Pooling | MAX_POOL_2D | MaxPool |
| multiply | Multiply | Eltwise | MUL | Mul |
| padding | ZeroPadding2D | PAD | Pad | |
| prelu | PReLU | PReLU | PRELU | Prelu |
| relu | ReLU | ReLU | RELU | Relu |
| relu6 | ReLU | RELU6 | Clip | |
| separable conv2d | SeparableConv2D | Conv | ||
| sigmoid | Sigmoid | Sigmoid | LOGISTIC | Sigmoid |
| squeeze | SQUEEZE | Squeeze | ||
| tanh | Tanh | Tanh | ||
| resize | UpSampling2D | RESIZE_BILINEAR / RESIZE_NEAREST_NEIGHBOR | Resize | |
| roi pooling | ROIPooling | MaxRoiPool |
- our tensorflow conversion tool is based on opensource "tf2onnx", please check "https://github.com/onnx/tensorflow-onnx/blob/r1.6/support_status.md" for the supported op information
- our pytorch conversion tool is based on onnx exporting api in torch.onnx, please check "https://pytorch.org/docs/stable/onnx.html#supported-operators" for the supported op information
- some operators could be replaced by onnx2onnx.py in order to fit the KL520/KL720 spec.
1 Keras to ONNX
For Keras, our converter support models from Keras 2.2.4. Note that tf.keras and Keras 2.3 is not supported. You may
need to export the model as tflite model and see section 5 for TF Lite model conversion.
Suppose there is an hdf5 model exported By Keras, you need to convert it to onnx by the following command:
python /workspace/libs/ONNX_Convertor/keras-onnx/generate_onnx.py -o absolute_path_of_output_model_file -O --duplicate-shared-weights absolute_path_of_input_model_file For example, if the model is /docker_mount/onet.hdf5, and you want to convert it to /docker_mount/onet.onnx, the
detailed command is:
python /workspace/libs/ONNX_Convertor/keras-onnx/generate_onnx.py -o /docker_mount/onet.onnx -O --duplicate-shared-weights /docker_mount/onet.hdf5Python API
Here is the Python API for the same purpose:
#[API]
ktc.onnx_optimizer.keras2onnx_flow(keras_model_path, optimize, input_shape)Return the converted onnx object. Convert keras model to onnx object.
Args:
- keras_model_path (str): the input hdf5/h5 model path.
- optimize (int, optional): optimization level. Defaults to 0.
- input_shape (List, optional): change the input shape if set. Only single input model is supported. Defaults to None.
Suppose there is an onet hdf5 model exported By Keras, you need to convert it to onnx by the following python code:
#[Note] You need to download the model first
result_m = ktc.onnx_optimizer.keras2onnx_flow('/data1/ConvertorExamples/keras_example/onet-0.417197.hdf5')In this line of python code, ktc.onnx_optimizer.keras2onnx_flow is the function that takes an hdf5 file path and convert the hdf5 into an onnx object. The return value result_m is the converted onnx object. You need to run the command in section 6 after this step.
There might be some warning log printed out by the TensorFlow backend, but we can ignore it since we do not actually run it. You can check whether the conversion succeed by checking whether the onnx file is generated.
You need to run the command in section 6 after this step.
Extra options
Input shape change(optional)
If there’s customized input shape for the model file, you need to use -I flag in the command. Here is an example:
python /workspace/libs/ONNX_Convertor/keras-onnx/generate_onnx.py abs_path_of_input_model -o abs_path_of_output_model -I 1 model_input_width model_input_height num_of_channel -O --duplicate-shared-weightsAdd RGBN to YYNN layer for Keras model(optional)
Some of the models might take gray scale images instead of RGB images as the input. Here is a small script to add an extra layer to let the model take RGB input.
cd /workspace/libs/ONNX_Convertor/keras-onnx && python rgba2yynn.py input_hdf5_file output_hdf5_file2 Pytorch to ONNX
We recommend using the Pytorch exported onnx file instead of the pth file, since the Pytorch does not has a
very good model save and load API. You can check TIPS below on how to export models to onnx.
We currently only support models exported by Pytorch version >=1.0.0, <=1.7.1, no matter it is a pth file or an onnx
file exported by torch.onnx. The PyTorch version in the toolchain docker is 1.7.1.
TIPS
You can use
torch.onnxto export your model into onnx format. Here is the Pytorch 1.7.1 version document fortorch.onnx. An example code for exporting the model is:
import torch.onnx
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, 'output.onnx', opset_version=11)In the example,
(1, 3, 224, 224)are batch size, input channel, input height and input width.modelis the model object you want to export.output.onnxis the output file.
Run pytorch_exported_onnx_preprocess with command line
Pytorch exported onnx needs to pass through a special optimization designed for pytorch exported models first.
Suppose the input file is called /docker_mount/resnet34.onnx and you want to save the optimized onnx as
/docker_mount/resnet34.opt.onnx. Here is the example
command:
python /workspace/libs/ONNX_Convertor/optimizer_scripts/pytorch_exported_onnx_preprocess.py /docker_mount/resnet34.onnx /docker_mount/resnet34.opt.onnxYou need to run the command in section 6 after this step.
Crash due to name conflict
If you meet the errors related to node not found or invalid input, this might be caused by a bug in the onnx
library. Please try using --no-bn-fusion flag.
Script pytorch2onnx.py is no longer available since toolchain v0.20.0. Please use torch.onnx to export the onnx model and use pytorch_exported_onnx_preprocess.py to optimize it instead.
Python API
The following is the Python API:
#[API]
ktc.onnx_optimizer.torch_exported_onnx_flow(m, disable_fuse_bn=False):Return the optimized model. Optimize the Pytorch exported onnx. Note that onnx2onnx_flow is still needed after running this optimization.
Args:
- m (ModelProto): the input onnx model
- disable_fuse_bn (bool, optional): do not fuse BN into Conv. Defaults to False.
Suppose the input file is loaded into a onnx object exported_m, here is the python code for pytorch exported onnx optimization:
#[API]
result_m = ktc.onnx_optimizer.torch_exported_onnx_flow(exported_m)In this line of python code, ktc.onnx_optimizer.torch_exported_onnx_flow is the function that takes an onnx object and optimize it. The return value result_m is the optimized onnx object. You need to run the command in section 6 after this step.
For the example in ConvertorExamples project, the whole process would be:
#[Note] You need to download the model first
import torch
import torch.onnx
# Load the pth saved model
pth_model = torch.load("/data1/ConvertorExamples/pytorch_example/resnet34.pth", map_location='cpu')
# Export the model
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(pth_model, dummy_input, '/data1/resnet34.onnx', opset_version=11)
# Load the exported onnx model as an onnx object
exported_m = onnx.load('/data1/resnet34.onnx')
# Optimize the exported onnx object
result_m = ktc.onnx_optimizer.torch_exported_onnx_flow(exported_m)There might be some warning log printed out by the Pytorch because our example model is a little old. But we can ignore it since we do not actually run it. You can check whether the conversion succeed by whether there is any exception raised.
Crash due to name conflict (Python API)
If you meet the errors related to node not found or invalid input, this might be caused by a bug in the onnx library.
Please try setting disable_fuse_bn to True. The code would be:
#[API]
result_m = ktc.onnx_optimizer.torch_exported_onnx_flow(exported_m, disable_fuse_bn=True)3 Caffe to ONNX
For toolchain later than v0.27.0, this script is no longer available.
For caffe, we only support model which can be loaded by Intel Caffe 1.0.
Suppose you have model structure definition file /docker_mount/mobilenetv2.prototxt and model weight file
/docker_mount/mobilenetv2.caffemodel and you want to output the result as /docker_mount/mobilenetv2.onnx, Here is
the example command:
python /workspace/libs/ONNX_Convertor/caffe-onnx/generate_onnx.py -o /docker_mount/mobilenetv2.onnx -w /docker_mount/mobilenetv2.caffemodel -n /docker_mount/mobilenetv2.prototxtYou need to run the command in section 6 after this step.
4 Tensorflow to ONNX
Tensorflow to onnx script only support Tensorflow 1.x and the operator support is very limited. If it cannot work on your model, please try to export the model as tflite and convert it using section 5.
Suppose you want to convert the model /docker_mount/mnist.pb to /docker_mount/mnist.onnx, here is the example
command:
python /workspace/libs/ONNX_Convertor/optimizer_scripts/tensorflow2onnx.py /docker_mount/mnist.pb /docker_mount/mnist.onnxYou need to run the command in section 6 after this step.
Python API
The following is the Python API for the same purpose:
#[API]
ktc.onnx_optimizer.caffe2onnx_flow(caffe_model_path, caffe_weight_path)Return the converted onnx object. Convert caffe model to onnx object.
Args:
- caffe_model_path (str): the input model definition (.prototxt).
- caffe_weight_path (str): the input weight file (.caffemodel).
Here we will use the example from ConvertorExamples. You can find two files for the caffe model: the model structure definition file mobilenetv2.prototxt and the model weight file mobilenetv2.caffemodel. Here is the example python code for model conversion:
#[Note] You need to download the model first
result_m = ktc.onnx_optimizer.caffe2onnx_flow('/data1/ConvertorExamples/caffe_example/mobilenetv2.prototxt', '/data1/ConvertorExamples/caffe_example/mobilenetv2.caffemodel')In this line of python code, ktc.onnx_optimizer.caffe2onnx_flow is the function that takes caffe model file paths and convert the them into an onnx object. The return value result_m is the converted onnx object.
You need to run the command in section 6 after this step.
5 TF Lite to ONNX
We only support unquantized TF Lite models for now. Also tensorflow 2 is not supported yet. If our converter cannot process your model correctly, please use the open-source tf2onnx. And use torch_exported_onnx_flow API for optimization after that.
python /workspace/libs/ONNX_Convertor/tflite-onnx/onnx_tflite/tflite2onnx.py -tflite path_of_input_tflite_model -save_path path_of_output_onnx_file -release_mode TrueFor the provided example model: model_unquant.tflite
python /workspace/libs/ONNX_Convertor/tflite-onnx/onnx_tflite/tflite2onnx.py -tflite /data1/tflite/model/model_unquant.tflite -save_path /data1/tflite/model/model_unquant.tflite.onnx -release_mode TruePython API
The following is our TFLite to ONNX Python API:
#[API]
ktc.onnx_optimizer.tflite2onnx_flow(tflite_path, release_mode, bottom_nodes)Return the converted onnx object. Convert tflite model to onnx object.
Args:
- tflite_path (str): the input tflite model path.
- release_mode (bool, optional): whether eliminate the transpose for channel first. Defaults to True.
- bottom_nodes (List, optional): nodes name in tflite model which is the bottom node of sub-graph. Defaults to [].
Suppose we are using the tflite file model_unquant.tflite from the ConvertorExamples, here is the example python code:
#[Note] You need to download the model first
result_m = ktc.onnx_optimizer.tflite2onnx_flow('/data1/ConvertorExamples/tflite_example/model_unquant.tflite')In this line of python code, ktc.onnx_optimizer.tflite2onnx_flow is the function that takes an tflite file path and convert the tflite into an onnx object. The return value result_m is the converted onnx object.
Then need to run the command in section 6.
TF Lite quant models:
If the tflite model provided is a quantized model, use the same command above to convert it into onnx. A user_config.json will be generated in the same path as -save_path provided. This file could be moved to the model input folder as one of the knerex input to do better quantization.
6 ONNX to ONNX (ONNX optimization)
We strongly recommend that all the onnx, including the onnx generated from the previous subsections, shall pass this API before going into the next section. This general onnx optimization API would modify the onnx graph to fit the toolchain and Kneron hardware specification. The optimization includes: inference internal value_info shapes, fuse consecutive operators, eliminate do-nothing operators, replace high-cost operators with low-cost operators, etc..
This ONNX optimizer is for ONNX with opset 12 or under. If you have a model with later opset, please check Kneronnxopt.
Suppose your model is input.onnx and the output model is called output.onnx:
python /workspace/libs/ONNX_Convertor/optimizer_scripts/onnx2onnx.py input.onnx -o output.onnx --add-bn -tCrash due to name conflict
If you meet the errors related to node not found or invalid input, this might be caused by a bug in the onnx
library. Please try using --no-bn-fusion flag.
MatMul optimization for kneron hardware
If your model has MatMul nodes with inputs of 3D instead of 2D and you want to deploy your model using Kneron hardware,
please use --opt-matmul flag to optimize the model. This flag allows the optimizer to split the input due to current
hardware input without affecting the correctness of calculation.
Python API
Here is the detailed ONNX optimization API:
#[API]
ktc.onnx_optimizer.onnx2onnx_flow(m, disable_fuse_bn=False, bgr=False, norm=False, rgba2yynn=False, eliminate_tail=False, opt_matmul=False, opt_720=False, duplicate_shared_weights=True)Return the optimized model. Optimize the onnx model.
Args:
- m (ModelProto): the input onnx ModelProto
- disable_fuse_bn (bool, optional): do not fuse BN into Conv. Defaults to False.
- bgr (bool, optional): add an Conv layer to convert rgb input to bgr. Defaults to False.
- norm (bool, optional): add an Conv layer to add 0.5 to the input. Defaults to False.
- rgba2yynn (bool, optional): add an Conv layer to convert rgb input to yynn . Defaults to False.
- eliminate_tail (bool, optional): remove the trailing NPU unsupported nodes. Defaults to False.
- opt_matmul (bool, optional): optimize the MatMul layers according to the NPU limit. Defaults to False.
- opt_720 (bool, optional): optimize the model for the kneron hardware kdp720. Defaults to False.
- duplicate_shared_weights(bool, optional): duplicate shared weights. Defaults to False.
Suppose we have a onnx object, here is the example python code:
optimized_m = ktc.onnx_optimizer.onnx2onnx_flow(result_m, eliminate_tail=True, opt_matmul=False)In this line of python code, ktc.onnx_optimizer.onnx2onnx_flow is the function that takes an onnx object and optimize it. The return value result_m is the converted onnx object.
Note that for hardware usage, eliminate_tail should be set to true as in the example. This option eliminate the no calculation operators and the npu unsupported operators (Reshape, Transpose, ...) at the last of the graph. However, since this changes the graph structure, you may need to check the model yourself and add the related functions into post-process to keep the algorithm consistent. If you only want to use onnx model for software testing, the eliminate_tail can be set to false to keep the model same as the input from the mathematics perspective. opt_matmul is also for hardware usage which optimize the MatMul nodes according to the NPU limit. By default, it is set to False. You only need to enable this flag if there are MatMul nodes with inputs more than 2D.
By the way, to save the model, you can use the following function from the onnx package.
# Save the onnx object optimized_m to path /data1/optimized.onnx.
onnx.save(optimized_m, '/data1/optimized.onnx')Crash due to name conflict
If you meet the errors related to node not found or invalid input, this might be caused by a bug in the onnx library.
Please try set disable_fuse_bn to True. The code would be:
#[API]
optimized_m = ktc.onnx_optimizer.onnx2onnx_flow(result_m, eliminate_tail=True, disable_fuse_bn=True)7 Model Editor
KL720 NPU supports most of the compute extensive OPs, such as Conv, BatchNormalization, Fully Connect/GEMM, in order to
speed up the model inference run time. On the other hand, there are some OPs that KL720 NPU cannot support well, such as
Softmax or Sigmod. However, these OPs usually are not compute extensive and they are better to execute in CPU.
Therefore, Kneron provides a model editor which is editor.py to help user modify the model so that KL720 NPU can run
the model more efficiently.
General Editor Guideline
Here are some general guideline to edit a model to take full advantage of KL720 NPU MAC efficiency:
Step 1: Start from each output node of the model, we should trace back to an operator that has significant compute
workload, such as GlobalAveragePool, Gemm(fully connect), or Conv. Then, we could cut to the output of that OP.
For example, there is a model looks Figure 4, and it has two output nodes: 350 and 349. From output node 349, we
can trace back to the Gemm above the red line because the Div, Clip, Add and Mul only have 1x5 dimension, and
these OPs are not very heavy computation. Since Mul and Div are not support in NPU, so it is recommend to cut the
rest of the OPs and let the model finish at the output of the Gemm (red line). For the other output node 350, since
it is the output of a Gemm, there is no need to do any more edition.
Step 2: If both input nodes and output nodes are channel last, and there is a Transpose after the input and before
the output, then the model is transposed into channel first. We can use the model editor to safely remove the
Transpose.
Step 3: If the input shape is not available or invalid, we can use the editor to give it a valid shape.
Step 4: The model need to pass onnx2onnx.py again after running the editor. See
section 6.
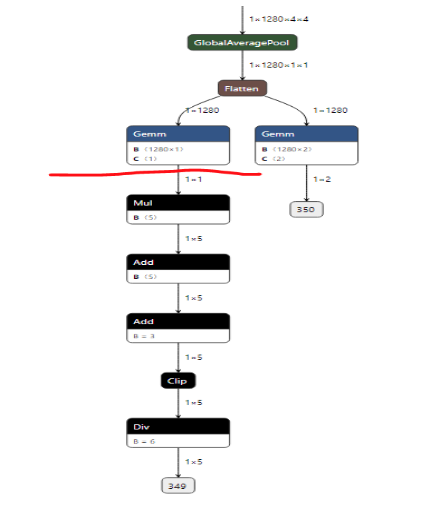
Figure 4. Pre-edited model
Feature
The script called editor.py is under the folder /workspace/libs/ONNX_Convertor/optimizer_scripts. It is a simple
ONNX editor which achieves the following functions:
- Add nop
BNorConvnodes. - Delete specific nodes or inputs.
- Cut the graph from certain node (Delete all the nodes following the node).
- Reshape inputs and outputs
- Rename the output.
Usage
editor.py [-h] [-c CUT_NODE [CUT_NODE ...]]
[--cut-type CUT_TYPE [CUT_TYPE ...]]
[-d DELETE_NODE [DELETE_NODE ...]]
[--delete-input DELETE_INPUT [DELETE_INPUT ...]]
[-i INPUT_CHANGE [INPUT_CHANGE ...]]
[-o OUTPUT_CHANGE [OUTPUT_CHANGE ...]]
[--add-conv ADD_CONV [ADD_CONV ...]]
[--add-bn ADD_BN [ADD_BN ...]]
in_file out_file
Edit an ONNX model. The processing sequence is 'delete nodes/values' -> 'add nodes' -> 'change shapes' -> 'cut node'.
Cutting is not recommended to be done with other operations together.
positional arguments:
in_file input ONNX FILE
out_file output ONNX FILE
optional arguments:
-h, --help show this help message and exit
-c CUT_NODE [CUT_NODE ...], --cut CUT_NODE [CUT_NODE ...]
remove nodes from the given nodes(inclusive)
--cut-type CUT_TYPE [CUT_TYPE ...]
remove nodes by type from the given nodes(inclusive)
-d DELETE_NODE [DELETE_NODE ...], --delete DELETE_NODE [DELETE_NODE ...]
delete nodes by names and only those nodes
--delete-input DELETE_INPUT [DELETE_INPUT ...]
delete inputs by names
-i INPUT_CHANGE [INPUT_CHANGE ...], --input INPUT_CHANGE [INPUT_CHANGE ...]
change input shape (e.g. -i 'input_0 1 3 224 224')
-o OUTPUT_CHANGE [OUTPUT_CHANGE ...], --output OUTPUT_CHANGE [OUTPUT_CHANGE ...]
change output shape (e.g. -o 'input_0 1 3 224 224')
--add-conv ADD_CONV [ADD_CONV ...]
add nop conv using specific input
--add-bn ADD_BN [ADD_BN ...]
add nop bn using specific inputPython API
Following are the Python APIs we provide.
Delete specific nodes
#[API]
ktc.onnx_optimizer.delete_nodes(model, node_names)Return the result onnx model. Delete nodes with the given names.
Args:
- model (onnx.ModelProto): the input onnx model.
- node_names (List[str]): a list of node names.
Delete specific inputs
#[API]
ktc.onnx_optimizer.delete_inputs(model, value_names)Return the result onnx model. Delete specific inputs
Args:
- model (onnx.ModelProto): input onnx model.
- value_names (List[str]): inputs to delete.
Delete specific outputs
#[API]
ktc.onnx_optimizer.delete_outputs(model, value_names)Return the result onnx model. Delete specific outputs
Args:
- model (onnx.ModelProto): input onnx model.
- value_names (List[str]): outputs to delete.
Cut the graph from the given node.
#[API]
ktc.onnx_optimizer.cut_graph_from_nodes(model, node_names)Return the result onnx model. Cut the graph from the given node. The difference between this function and the
delete_node is that this function also delete all the following nodes after the specific nodes.
Args:
- model (onnx.ModelProto): the input onnx model.
- node_names (List[str]): a list of node names.
Cut the graph from the given operator type.
#[API]
ktc.onnx_optimizer.remove_nodes_with_types(model, type_names)Return the result onnx model. Cut the graph from the nodes with specific operation types. Similar behaviour to
cut_graph_from_nodes.
Args:
- model (onnx.ModelProto): the input onnx model.
- type_names (List[str]): operator types to cut from.
Change input/output shapes
#[API]
ktc.onnx_optimizer.change_input_output_shapes(model, input_shape_mapping=None, output_shape_mapping=None)Return the result onnx model. Change input shapes and output shapes.
Args:
- model (onnx.ModelProto): input onnx model.
- input_shape_mapping (Dict, optional): mapping from input names to the shapes to change. Defaults to None.
- output_shape_mapping (Dict, optional): mapping from output names to the shapes to change. Defaults to None.
Add do-nothing Conv nodes after specific values
#[API]
ktc.onnx_optimizer.add_conv_after(model, value_names)Return the result onnx model. Add a do-nothing Conv node after the specific value.
Args:
- model (onnx.ModelProto): input onnx model.
- value_names (List[str]): values after which we add Conv.
Add do-nothing BN nodes after specific values
#[API]
ktc.onnx_optimizer.add_bn_after(model, value_names)Return the result onnx model. Add a do-nothing BN node after the specific value.
Args:
- model (onnx.ModelProto): input onnx model.
- value_names (List[str]): values after which we add BN.
Rename an output
#[API]
ktc.onnx_optimizer.rename_output(model, old_name, new_name)Return the result onnx model. Rename the specific output
Args:
- model (onnx.ModelProto): input onnx model.
- old_name (str): old output name.
- new_name (str): new output name.
Input pixel shift
#[API]
ktc.onnx_optimizer.pixel_modify(model, scale, bias)Return the result onnx model. Add a special BN node to adjust the input range. Currently only support single input model.
Args:
- model (onnx.ModelProto): input onnx model.
- scale (List[float]): the scale of the BN node.
- bias (List[float]): the bias of the BN node
8 ONNX Updater
For existed onnx models with the previous version of the opset, we provide the following scripts to update your model.
Note that after running any of the following scripts, you may still need to run onnx2onnx.py.
# For ONNX opset 8 to opset 9:
python /workspace/libs/ONNX_Convertor/optimizer_scripts/opset_8_to_9.py input.onnx output.onnx
# For ONNX opset 9 to opset 11:
python /workspace/libs/ONNX_Convertor/optimizer_scripts/opset_9_to_11.py input.onnx output.onnx
# For ONNX opset 10 to opset 11:
python /workspace/libs/ONNX_Convertor/optimizer_scripts/opset_10_to_11.py input.onnx output.onnxPython API
Here is the Python API:
#[API]
ktc.onnx_optimizer.convert_opset_8_to_9(model)
ktc.onnx_optimizer.convert_opset_9_to_11(model)
ktc.onnx_optimizer.convert_opset_10_to_11(model)Return the updated onnx model. Update model ir_version from 4 to 6 and update opset from 9 to 11.
Args:
- model (onnx.ModelProto): input onnx model.
Here is an example usage.
#[Note] old_m is the opset 9 onnx model object.
new_m = ktc.onnx_optimizer.convert_opset_9_to_11(old_m)In this line of python code, ktc.onnx_optimizer.convert_opset_9_to_11 is the function that takes an old version onnx object and upgrade it. The return value new_m is the converted onnx object. It need to take one more optimization step (section 3.1.5) before going into the next section. Even if you have already passed optimizer before, we still recommend you do it again after this upgrade.